很多文章的报道都是由微观而宏观,今日小编讲给大家带来的关于融合在线和离线强化学习的算法的资讯也不例外,希翼可以在一定的程度上开阔你们的视野!y有对融合在线和离线强化学习的算法这篇文章感兴趣的小伙伴可以一起来看看
近年来,越来越多的研究人员已经开辟了基于人工神经网络(ANN)的模型,可以使用称为强化学习(RL)的技术对其进行训练。RL要求训练人工代理以通过在他们表现良好(例如,正确地对图像进行正确分类)时给予他们“奖励”来解决各种任务。
到目前为止,大多数基于人工神经网络的模型进行了培训采纳网上RL方法,其中,这是从来没有接触到代理人的任务是通过与网络虚拟环境交互设计,完全可以学习。但是,这种方法可能非常昂贵,费时且效率低下。
最近,一些研究探究了离线训练模型的可能性。在这种情况下,人工代理通过分析固定的数据集学习完成给定的任务,因此不会主动与虚拟环境进行交互。尽管离线RL方法在某些任务上取得了可喜的结果,但它们不同意 代理实时学习。
加州大学伯克利分校的研究人员最近推出了一种新的算法,该算法使用在线和离线RL方法进行了训练。该算法在arXiv上预先发表的一篇论文中提出,最初是针对大量离线数据进行训练的,但同时它也完成了一系列的在线训练试验。
进行这项研究的研究人员之一Ashvin Nair告诉TechXplore:“我们的工作重点是在现实世界的机器人环境中不断遇到的两个案例之间的情况。”“通常,在尝试解决机器人技术问题时,研究人员拥有一些先验数据(例如,一些有关如何解决任务的专家演示或您上次执行的实验中的一些数据),并且希翼利用先验数据来解决任务部分地,但是然后能够微调解决方案以通过少量交互来掌握它。”
在回忆过去的RL文献时,Nair和他的同事意识到,以前开辟的模型在首先进行脱机训练然后进行在线微调时效果不佳。这通常是因为他们学习速度太慢或在培训期间未充分利用离线数据集。
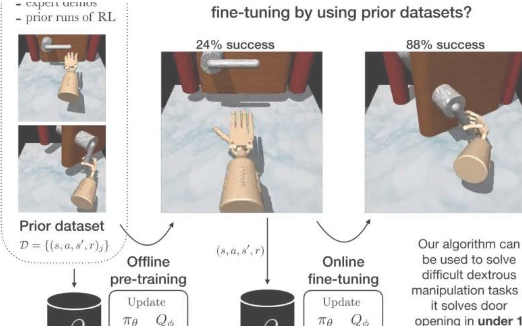
在他们的研究中,研究人员深入研究了现有模型的局限性,然后设计了一种可以克服这些问题的算法。当离线对大量数据进行预训练时,他们创建的算法可以实现令人中意的性能。这样,当它在虚拟在线环境中受到积极培训时,它便可以快速掌握其计划在以后完成的任务。
Nair解释说:“我们的论文解决了一个妨碍我们前进的常见问题:我们向来在使机器人从头开始学习任务,而不是能够将现有的数据集用于RL。”“实际上,这是由于意识到我们对一个单独想法的实验周期花费了太多时间和太多精力来评估在现实世界中的机器人上的运行情况,因此我们需要一种通过预训练来评估想法的方法根据我们已经拥有的数据,并且仅进行少量额外的实际交互。”
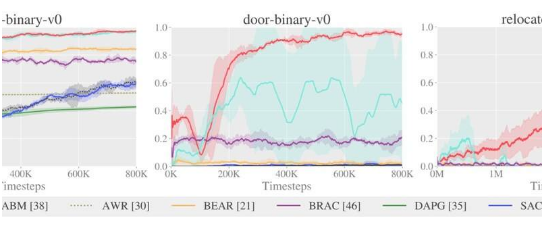
Nair和他的同事确定了以前通过RL训练的模型的三个主要局限性。首先,他们观察到,通常使用在线策略技术(例如,优势加权回归(AWR)和示范性增强策略梯度(DAPG))来微调在线模型,与离线策略方法相比,它们学习起来通常很慢。
此外,研究人员观察到,在离线数据集上进行训练时,诸如软演员批判(SAC)方法之类的非政策方法通常并没有太大改进。最后,他们发现脱机训练模型的技术,例如引导错误累积减少(BEAR),行为正则化演员批判家(BRAC)和优势行为模型(ABM)在脱机预训练阶段通常效果很好,但是它们的性能确实当他们在网上接受培训时,进步不大。这主要是因为它们依赖行为模型,该行为模型在尝试概述数据的总体分布和相应的学习策略时效果很好,而在在线环境中对模型进行微调时效果不佳。
Nair表示:“面对这些挑战,我们开辟了优势加权演员批判家(AWAC),这是一种脱离政策的演员批判家算法,它不依赖行为模型来保持数据分布的密切性。”“相反,我们证明了我们可以导出一种通过采样隐式保持接近数据的算法。”
Nair和他的同事开辟的AWAC算法可以离线离线进行预训练,也可以使用专门为离线训练而设计的技术。但是,当对其进行在线培训时,其性能会进一步提高,并有很大的提高。
研究人员评估了他们的算法在不同机灵操作任务上的性能,这些任务以三个关键方面为特征,即复杂的不延续接触,非常稀疏的二进制奖励和30个关节的操纵。更具体地说,他们的算法经过训练可以操纵机器人的运动,从而使其可以旋转手中的笔,打开门或捡起球并将其移动到所需位置。对于每个任务,Nair和他的同事在一个离线数据集上训练了该算法,该数据集包含25个人类示威游行和500条偏离政策的轨迹,这是使用一种称为行为克隆的技术实现的。
Nair说:“第一个任务是笔旋转,相对来说比较简单,最终有许多方法可以解决该问题,但是AWAC是最快的。”“惟独AWAC才干解决第二和第三项任务。先前的方法由于种种原因而失败,主要是因为它们无法获得合理的初始政策来收集良好的勘探数据,或者它们无法从交互数据中进行在线学习。”
Nair和他的同事将他们的AWAC算法与通过离线或在线RL训练的其他八种方法进行了比较,发现这是唯一能够始终如一地解决他们对其进行测试的困难操作任务的方法。他们的算法还可以解决较简单的MuJoCo基准任务,并且比以前开辟的方法更快地完成推送任务,可以从次优,随机生成的数据中学习。
将来,该算法可以支持使用RL在更广泛的任务上训练模型。其他研究团队也可以从他们的工作中吸收灵感,并设计出结合离线和在线培训的类似RL方法。
Nair表示:“展望未来,我们计划利用AWAC来加快实验速度,并通过利用现有数据来稳定对新任务的培训。”“我们真正兴奋的方向是扩大用于RL的数据量,以便开始看到跨任务以及对象的视觉和物理特性的显着概括。”
