很多文章的报道都是由微观而宏观,今日小编讲给大家带来的关于用于AI硬件加速器的基于电容器的架构 的资讯也不例外,希翼可以在一定的程度上开阔你们的视野!y有对用于AI硬件加速器的基于电容器的架构 这篇文章感兴趣的小伙伴可以一起来看看
IBM通过基于电容器的交叉点阵列用于模拟神经网络,超越了数字技术,在深度学习计算中显示出潜在的数量级改进。模拟计算架构利用某些存储设备的存储能力和物理属性,不仅用于存储信息,而且还用于执行计算。这有可能极大地减少计算机所需的时间和能源,因为不需要在内存和处理器之间穿梭数据。缺点可能是计算精度降低,但是对于不需要高精度的系统,这是正确的权衡。
在模拟神经网络(NN)中,基于非易失性存储器(NVM)的交叉点阵列已在推理任务方面取得了可喜的成果。然而,对于NVM设备而言,难以对NN进行高精度训练,因为成功的训练取决于保持NN 权重的增量变化较小(需要大约1,000个更新状态)和对称(以便使正负更新平均平衡)。这些问题可以通过使用电容器来解决。如果电子数量多,由于可以延续增加或减少电荷,因此可以实现模拟和对称分量更新。我们在2018年VLSI技术研讨会上提出了一种用于模拟神经网络的基于电容器的交叉点阵列。新的架构实现了分量更新的对称性和线性记录。
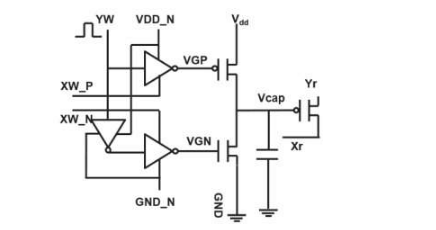
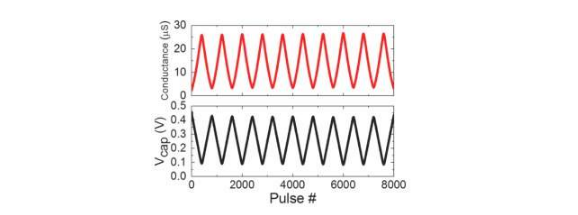
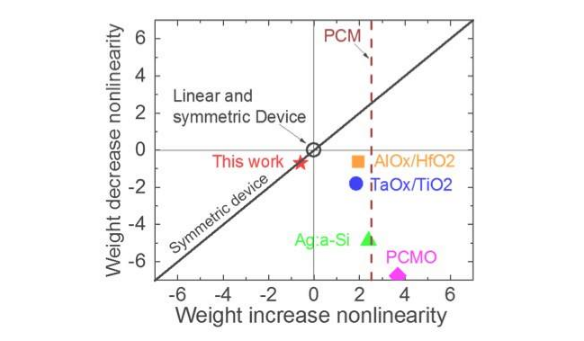
图1显示了基于电容器的交叉点阵列的单位单元示意图。关键组件是连接到读出场效应晶体管(FET)的电容器。电容器上的电荷代表突触权重,电容器通过两个电流源FET充电和放电。图2分别显示了十个周期的400个正更新,然后是400个负更新,分别测量了一个单元的读出FET的电导变化和相应的电容器电压。图3比较了基于电容器的模拟突触与其他NVM技术的实验非线性更新因子。基于电容器的单元电池提供了迄今为止证明的最佳对称性和线性。图4演示了在2×2阵列上的并行权重更新。
即使电容器易失,也可以在分量更新过程中补偿泄漏。由于训练反复进行前,后和权重更新循环,因此前一个循环衰减后的权重将用于下一个循环的训练并得到更新。因此,不需要故意的刷新周期。我们使用完全连接的网络测试了保留时间对训练的影响。它具有一个输入层,两个隐藏层和一个输出层(图5),并通过随机梯度下降和反向传播在MNIST数据集上进行了训练。假设每层的训练周期长度(向前+向后+更新)为200 ns,并且突触权重随RC时间常数τ衰减,我们发现当τ> 106×训练周期时,电容器电荷损耗对训练精度的影响可以忽略不计长度(图6)。我们还测试了卷积网络的保留时间要求。我们的测试网络有两个卷积层,两个卷积层和两个完全连接的层(图7)。由于卷积层中的分量分配(重用),因此对于卷积层的保留要求卷积神经网络(CNN)大约大600(图8)。
对于完全连接的和卷积神经网络,我们估量了这种基于电容器的阵列的可扩展性与泄漏的函数关系(图9)。圆形数据点表明,电容器随传输晶体管泄漏呈线性比例变化。方形数据点表明,当泄漏较大时,电池面积由电容器决定;当泄漏电流较小时,该区域将由单元中的FET支配。对于具有1 fA /单元泄漏的DRAM技术,对于完全连接的神经网络,电容器<1fF /单元需要电容器,而CNN则需要〜100 fF /单元。对于更大的输入和更多层的可伸缩性需要进一步研究。即使在输入变大时可能需要更大的电容器,我们的初步结果(将要公布)表明该网络/算法优化可以减少电容器需求。
IBM现在正在研究具有优化模拟行为的新型理想内存。由于已有技术和工艺可用,这些电容器将同意 加快模拟AI内核的实现。
除了我们的电容器方法外,IBM正在探究用于模拟存储器和计算的其他新颖元件,例如相变存储器(PCM)和电阻式RAM(RRAM)。这些元素在细胞面积,保留,对称性和成熟度方面有所不同。模拟加速器是IBM Research AI的AI硬件加速器产品线的一个组成部分。开辟流程首先要从现有的GPU加速器中获得最大收益,然后是利用近似计算的创新数字AI内核。
