很多文章的报道都是由微观而宏观,今日小编讲给大家带来的关于微软的AI根据上下文重写句子的资讯也不例外,希翼可以在一定的程度上开阔你们的视野!y有对微软的AI根据上下文重写句子这篇文章感兴趣的小伙伴可以一起来看看
听说过上下文建模吗?它定义了上下文数据的结构和维护方式,并且在开放域对话中起着举足轻重的作用。因此,Microsoft的研究人员最近研究了一种新颖的方法,该方法涉及通过考虑上下文历史记录来重写对话回合中的最后话语(即一系列话语)。他们在一份详细介绍其工作的预印本论文(“用于开放域对话的无监督上下文重写”)中,根据经验结果表明,它在重写质量和多回合响应生成方面达到了最新的基准。

正如研究人员所解释的,对话上下文提出了句子建模中不存在的挑战,包括主题转换,共指(例如,他,他,她,它,他们)以及长期依存关系。大多数系统通过将关键字附加到最后一声发声或通过使用AI模型学习数字表示来解决这些问题,但常常遇到障碍,例如无法选择正确的关键字或处理较长的上下文。
微软为应用程序开辟人员提供的交易比苹果更好
这就是团队方法的用武之地。它通过考虑上下文信息来重新制定对话中的最后一种话语,目的是生成一个自包含的话语,这种话语既没有共同参照,又不依赖于历史上的其他话语。例如,“我讨厌喝咖啡。为什么?很好吃”变成“为什么讨厌喝咖啡?“好吃”,用“ it”(在上下文中指的是咖啡)和“ Why?”(缩写为“为什么讨厌喝咖啡?”)两个词作为参考。

研究人员设计了一种机器学习系统-上下文重写网络(CRN)-以实现端到端的流程自动化。它由一个序列到序列模型组成,该模型将固定长度的话语映射到固定长度的重写句子,并具有单独的关注机制,该机制通过专注于最后一次发音中的不同单词来帮助直接从上下文复制单词。
该团队首先使用伪数据对模型进行了训练,该伪数据是通过将从上下文中提取的关键字插入到原始的最后语音中而生成的。然后,为了让最终响应影响重写过程,他们采纳了强化学习,这是一种AI培训技术,利用奖励将系统推向目标。
在一系列实验中,该团队评估了他们的方法在几种重写质量,多回合响应生成,多回合响应选择以及基于端到端检索的任务上的应用。他们注意到,他们的模型在强化学习后间或 会变得不稳定,因为它倾向于从上下文中提取更多的单词,但是通常,它“显着”改善了话语的多样性。
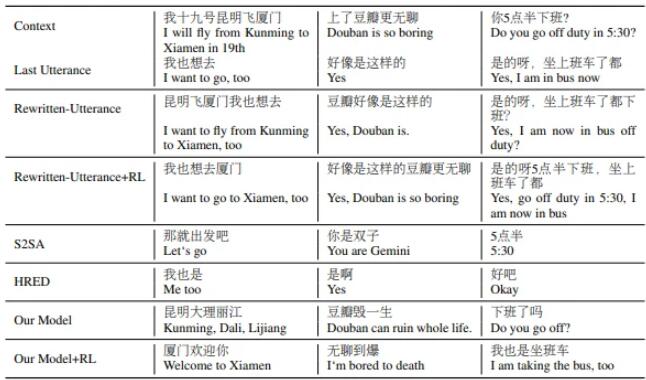
上图:微软的AI模型重写句子。
该团队认为他们的工作朝着更加可解释和可操纵的上下文建模迈出了一步,主要是因为显式的上下文重写结果更易于调试和分析。他们写道:“重写上下文类似于人类参考。”“我们的模型可以从嘈杂的上下文中提取重要的关键字,并将其插入到最后的发音中,[使其变得不仅易于操纵和解释...,而且还[直接用于]将信息传递给[最后的发音]。 ”
